소셜 미디어 감성분석을 통한 주가 예측
이 글은 Entrue Journal of Information Technology 에 기고된 논문인「소셜 미디어 감성분석을 통한 주가 등락 예측에 관한 연구 - A Study on the Stock Market Prediction Based on Sentiment Analysis of Social Media - 김영민·정석재·이석준」을 필자의 시각에서 이해하기 쉽게 소개하는 글입니다.
소셜 미디어(Social Media)¶
오늘 소개할 흥미로운 논문은 「소셜 미디어 감성분석을 통한 주가 등락 예측에 관한 연구」 라는 제목의 논문입니다. 그렇다면 먼저 제목에 처음 나오는 단어인 소셜 미디어에 대해 알아보도록 하겠습니다. 소셜 미디어의 사전적 정의는 다음과 같습니다.
소셜 미디어(social media)는 개방, 참여, 공유의 가치로 요약되는 웹 2.0시대의 도래에 따라 소셜 네트워크의 기반 위에서 개인의 생각이 나 의견, 경험, 정보 등을 서로 공유하고 타인과의 관계를 생성 또는 확장시킬 수 있는 개방화된 온라인 플랫폼을 의미한다.
소셜 미디어의 가장 큰 특징은 양방향성입니다. 소셜 미디어는 TV, 신문, 잡지 등의 기존 매체의 일방적 독백을 사회적 매체의 대화로 변환시키고,
그 이용자들이 콘텐츠 소비자임과 동시에 콘텐츠 생산자가 되는 것을 가능케 함으로써 정보의 민주화와 개방화를 촉진시키고 있습니다.
소셜 미디어는 이렇게 이용자들이 자발적으로 참여하고 정보를 공유하며 콘텐츠를 만들어 나간다는 특성을 가지고 있습니다.
이 논문에서는 국내 대표적인 소셜 미디어로 알려진 네이버, 다음 커뮤니케이션과 주가 정보 제공 사이트인 팍스넷이 제공하고 있는 특정 주식 종목에 대해 참여자들이 자유롭게
글을 남길 수 있는 증권 종목 토론실로부터 사용자들의 메시지를 추출하여 자료 분석에 사용하였습니다.
자연어 처리 기술과 감성 분석(Sentiment Analysis)¶
이제 논문 제목에 나오는 감성 분석이 무엇인지 살펴보도록 하겠습니다. 감성 분석(Sentiment Analysis)은 ‘오피니언 마이닝(Opinion Mining)’으로 도 불리는데, 이는 텍스트에 나타난 사람들의 태도, 의견, 성향과 같은 주관적 인 데이터를 분석하는 자연어 처리 기술입니다. 원문인 ‘sentiment’를 번역해 ‘감성 분석’, 혹은 ‘감정 분석’으 로도 불리나 이 글에서는 현재 널리 쓰이고 있는 ‘감성 분석’이라는 용어를 사용하도록 하겠습니다.
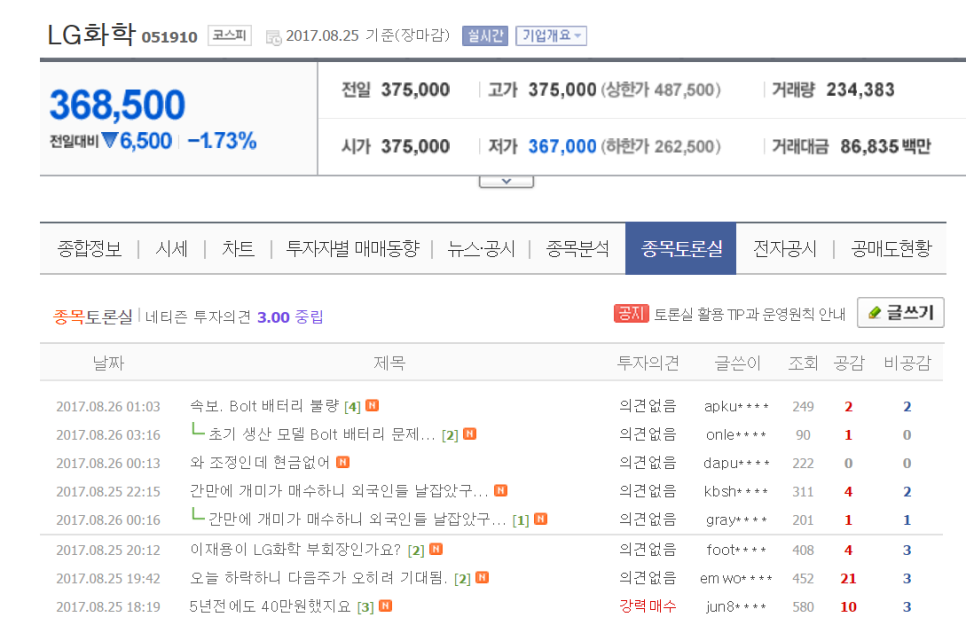
증권 종목토론실에 들어가 보면 위의 사진과 같이 이용자들의 다양한 의견을 접할 수 있습니다. 이러한 데이터는 자연언어에 의한 서술로 표현되는 범주형 데이터이기 때문에 정성적 데이터라고 부릅니다. 컴퓨터는 정확한 수치로 이루어진 정량적 데이터만을 처리할 수 있습니다. 따라서 그동안 컴퓨터는 이용자들이 남긴 수많은 정성적 데이터를 처리할 수 없었습니다. 하지만, 이는 인공지능 분야가 발전함으로써, 더 이상 사실이 아니게 되었습니다.
인공지능을 활용할 수 있는 분야 중, 컴퓨터공학자들이 늘 관심을 갖고 연구하는 분야가 하나 있습니다. 바로 자연어 처리(Natural Language Processing, 줄여서 NLP)라는 분야입니다.
이 분야를 간단히 설명하자면 컴퓨터에게 인간의 언어를 이해시키고, 학습시키는 분야라고 할 수 있습니다. 요즈음 시중에 많이 나오고 있는 인공지능 스피커 또는 아이폰을 사용하면 내 지시에
대답해주는 시리(Siri) 등의 다양한 분야에서 NLP 기술을 활용하고 있습니다.

감정 분석은 이런 NLP 기술을 이용한 분석입니다. 감성 분석에는 여러 가지 기법이 있습니다. 이 중에서 감정 단어 사전은 비교적 간단하면서도 정확한 방법입니다.
감정 단어 사전이란 긍정적이거나 부정적인 감정을 나타내는 단어들에 극성 값을 부여하여 모아놓은 사전입니다. 영어에는 SentiWordnet, WordNetAffect 등이 있습니다.
국내에서도 이러한 감성사전 구축의 필요성에 따라 한국어 감성사전에 대한 연구가 현재 활발하게 진행되고 있지만 아직까지 공신력 있는 한국어 감성사전은 개발되지 않은 상태입니다.
이러한 한국어 감성사전의 부재로 인한 해결 방안으로 이 연구에서는 구글 API를 통해 언어를 영어로 번역(또는 한->일->영으로 번역) 한 뒤 감성 분석을 진행합니다.
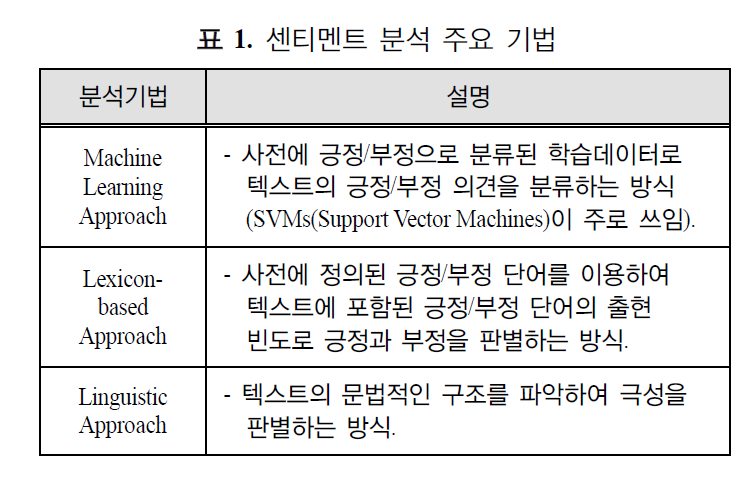
또 영문 번역을 실시하여 감성 분석을 진행하기 때문에 오역 문제를 발생시킬 가능성이 크게 됩니다. 따라서 이 논문에서는 문맥에 따라 극성을 판단하는 Linguistic 방법이 아닌
긍정과 부정 단어의 빈도를 판별하는 Lexicon-based 방법을 사용합니다.
이제 이런 분석 과정을 거치게 되면 게시물 별 극성 값이 계산되어 나오게 됩니다. 정성적 데이터를 정량적 수치 데이터로 변환해 준 것입니다. 극성 값이 0보다 크면 긍정, 0보다 작은 경우 부정으로 설정합니다. 즉, 감성 분석을 통해 해당 게시물의 긍정 단어 개수가 부정 단어 개수보다 많으면 긍정, 부정 단어 개수가 긍정 단어 개수보다 많으면 부정으로 정의합니다. 이렇게 나온 긍정과 부정에 각각 상승과 하락을 매치하여 주가 예측을 실행합니다.
감성사전에 단어별로 극성의 가중치를 두어 계산하면 더욱 유의미한 분석 결과를 얻을 수 있지만 한글을 영문으로 번역하는 절차에서 오역 문제를 보완하고자 단순히 긍정과 부정으로 나뉜 감성사전을 활용하여 어휘의 빈도를 통한 감성 분석을 진행하였습니다.
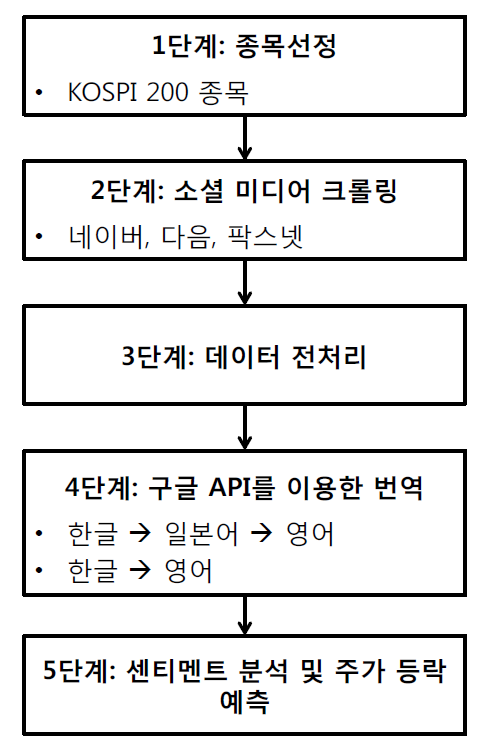
소셜 미디어 크롤링
크롤링이란 무수히 많은 웹사이트 상의 문서들을 수집하여 검색 대상의 색인으로 포함시키는 기술을 의미합니다. 이 연구에서 수집된 데이터는 종목토론실의 이용자들이 올린 게시글로 날짜, 제목, 내용, 댓글로 구성됩니다.
데이터 전처리(Data pre-processing)
전처리 과정은 연구의 정확도를 향상시키기 위해 사전에 준비된 데이터를 적합한 형태로 처리해 주는 과정입니다. 3단계에서는 여러 가지 특수문자와 같이 불필요한 데이터를 제거하고 유사한 내용을 반복적으로 사용하여 선동적 메시지를 담고 있는, 소위 “도배글” 과 같은 데이터를 제거합니다.
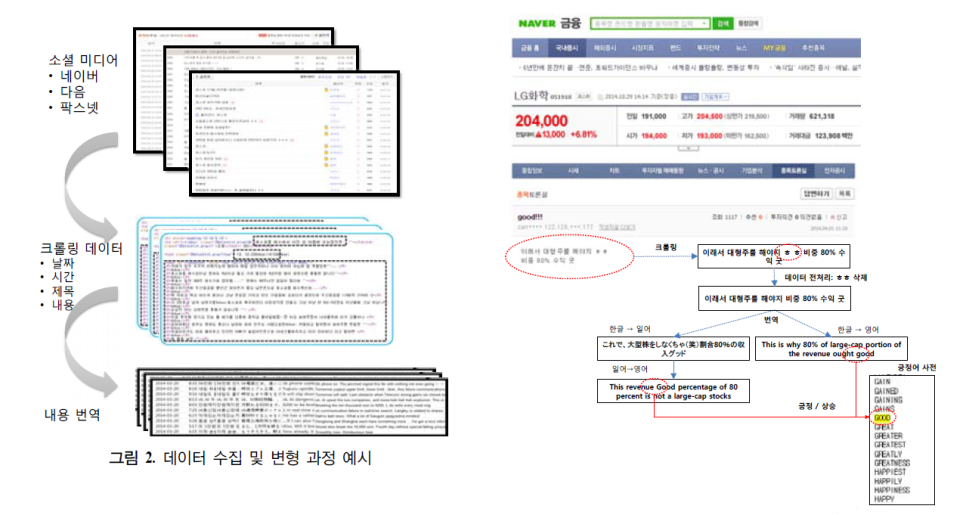
아래 그림에 간단한 도식화를 첨부하였습니다. 왼쪽 그림은 소셜 미디어에서 데이터를 수집하고 분석을 위한 데이터 변형 과정을 간략히 보여 주고 있습니다. 오른쪽 그림은 실제로 네이버 금융 종목토론실에서 LG화학 종목과 관련된 메시지를 추출하여 분석하는 모습을 보여 주고 있습니다.
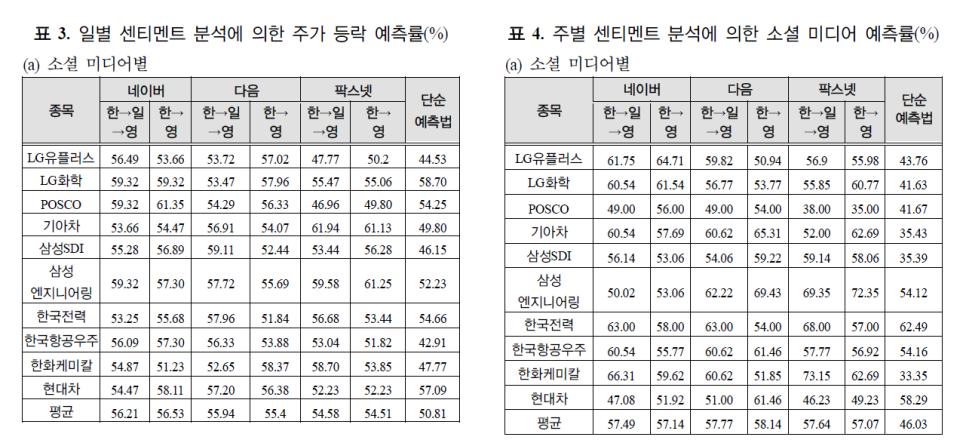
각각 커뮤니티의 자료를 이용해 예측한 결과는 위와 같습니다. 여기서 비교에 사용된 단순 예측법이란 어제 주가가 올랐으면 오늘도 상승할 거라고 가정하고 떨어졌다면 오늘도 하락 할 것이라고 가정하는 예측 방법입니다.
표를 통해서 일별보다는 주별 예측의 정확도가 높음을 확인할 수 있습니다. 또 번역 과정(한 -> 일 -> 영, 한 -> 영)에 의한 결과의 차이는 T-검정을 통해 통계적으로 유의한 차이가 없음을 밝혀 낼 수 있습니다.
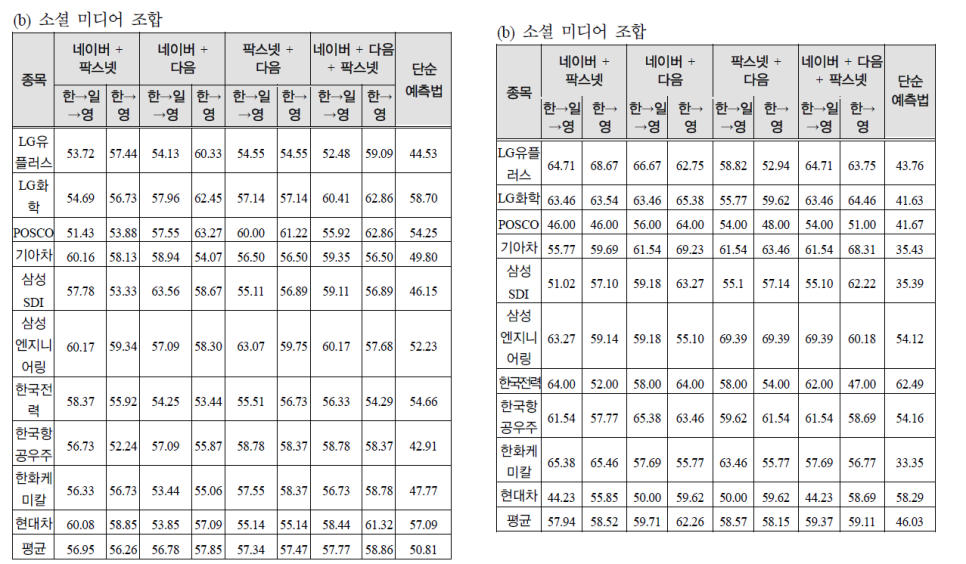
위의 표를 통해서 개별 미디어에서 분석을 진행하는 것 보다 두 개 이상을 조합하여 분석을 진행할 때 정확도가 상승함을 확인할 수 있습니다. ‘네이버 + 다음’ 의 평균 예측률은 62.26%로, 단순 예측 법보다 약 16%정도 높은 것을 볼 수 있습니다. ‘네이버 + 다음 + 팍스넷’ 조합의 예측률 또한 약 60% 정도 일별 주가 예측보다 다소 상승한 것을 파악할 수 있습니다. 즉, 분석한 메시지 개수가 많으면 많을수록 주가 예측에 도움이 된다고 할 수 있습니다.
저자가 뽑은 연구의 한계점으로는 메시지 개수의 제약으로 인해 더 많은 주식 종목들을 표본으로 사용하지 못하고 10개의 표본만 사용했다는 점, 국내 주식시장 관련 감성사전의 부재에 대한 아쉬움이 있었습니다. 필자는 개인적으로 이용자들이 올린 게시글(정성적 데이터)를 정량적으로 변환(하나의 지표화) 해서 계량적 정성 분석에 활용할 수 있지 않을까? 라는 생각을 해 보았습니다. 이런 생각들과 함께 오늘의 글을 마무리하도록 하겠습니다. 다음 글에서도 흥미로운 주제로 찾아뵙도록 하겠습니다!